
This guide will show you how to use Python to:
- Log into LinkedIn Sales Navigator
- Search by company name
- Filter search results
- Scrape returned data
My code can be found on Github but I’ll explain how each section works, if you’d like to customize it for your own project.
What is LinkedIn Sales Navigator?
LinkedIn Sales Navigator is LinkedIn’s paid sales toolset. It mines all that data you and I have freely handed to LI over the years and gives sales organizations the power to create leads and manage their pipeline. It can integrate with your CRM to personalize your results and show additional information.
LI Sales Navigator markets itself to sellers but its data aggregations are also a gold mine for creating insights. For example, I wanted data on employees’ tenure with their company. This would be very difficult using vanilla LinkedIn–I’d have to click into each employee’s profile individually.
LinkedIn Sales Navigator brings that data directly to you and allows you to filter results by geography or years of experience. The screenshot below gives you an idea of the kind of data returned for employees (known as leads in LinkedIn parlance) but similar aggregations are performed on companies (known as accounts).
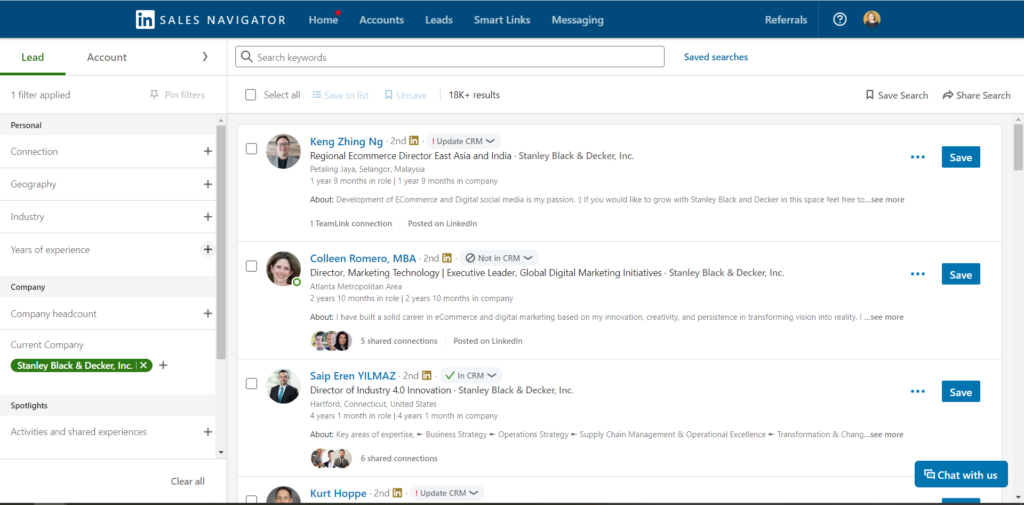
Is scraping legal?
Scraping publicly accessible online data is legal, as ruled by a U.S. appeals court.
But just because scraping is legal doesn’t mean LinkedIn is going to make this easy for us. The code I’ll walk through will show some of the challenges you might run into when attempting to scrape LI but beware! Scraping is software’s equivalent of the Castaway raft—hacked-together and good for one ride only. LI changes its website frequently and what worked one day may not work the next.

How to scrape
Setting up
I used the Python library selenium to scrape data from LinkedIn Sales Navigator within the Chrome browser. You’ll need to run the following from a terminal window to install the required libraries:
pip install selenium
pip install webdriver_managerIt’s best practice to set up a dedicated virtual environment for this task. I recommend conda, though other options include virtualenv or poetry. Check out this helpful resource to access your new conda environment from a Jupyter Notebook.
Logging in
I chose to wrap my scraping functions within a class named LIScraper. An object-oriented approach allowed me to create new Chrome sessions with each instance of LIScraper, simplifying the debugging process.
The only input when instantiating the class is path_to_li_creds. You’ll need to store your LinkedIn username and password within a text file at that destination. We can then instantiate our scraper as shown below.
scraper = LIScraper(path_to_li_creds='li_creds.txt')
scraper.log_in_to_li_sales_nav()This code will open up a new Chrome window, navigate to the LinkedIn Sales Navigator home page, and log in using the provided credentials.
Start with the goal
Before we go any further, let’s take a quick look at the master function gather_all_data_for_company that accomplishes my specific scraping task.
I wanted to search for a given company, find all current employees with the keyword “data” in their job title, and then scrape their job title and company tenure from the website.
Let’s break this down sequentially.
1. Search by company
I needed to scrape results for 300 companies. I didn’t have the time or patience to manually review LI’s search results for each company name. So I programmatically entered in each company name from my list and assumed that the first search result would be the correct one.
This was a faulty assumption.
I then tried to guide the search algorithm by restricting results to companies within my CRM (crm_only=True) but this still did not guarantee that the first search result was the right one.
As a safeguard, I logged the name of the company whose data I was collecting and then manually reviewed all 300 matches after my scraping job finished to find those that did not match my expectations. For any mismatches, I manually triggered a scraping job after selecting the correct company from LI’s search results.
2. Search for employees
I then wanted to find all job titles containing a specific keyword.
You might notice several layers of nested try-except clauses in this function. I could not understand why the code would run successfully one minute but would then fail when I tried to execute it again immediately after. Alas, the problem was not in how I selected the element on the page but in when I attempted to select it.
I just needed to add more time (ex. time.sleep(4)) before executing my next step. Webpages can take a long time to load all their elements, and this loading time can vary wildly between sessions.
Helpful hint: If your scraping code does not execute successfully in a deterministic manner, add more time between steps.
3. Gather the data
We’re now ready to scrape some data!
First, we scroll to the bottom of the page to allow all the results to load. Then we assess how many results LI returned.
CAUTION: The number of results actually returned by LinkedIn does not always match the number LinkedIn claims to have returned.
I had initially tried to scrape 25 results per page or the remainder if the number of results returned was not an even multiple of 25. For example, if the number of results LI claimed to have returned was 84, I’d scrape three pages of 25 results each and then scrape the remaining 9 results on the last page.
But my job would throw an error when this last page contained just 8 results. Why would LI claim to have found 84 results when in reality, it only had 83? That remains one of the great mysteries of the internet.
To get around this issue, I counted the number of headshots on the page to indicate how many results I’d need to scrape.
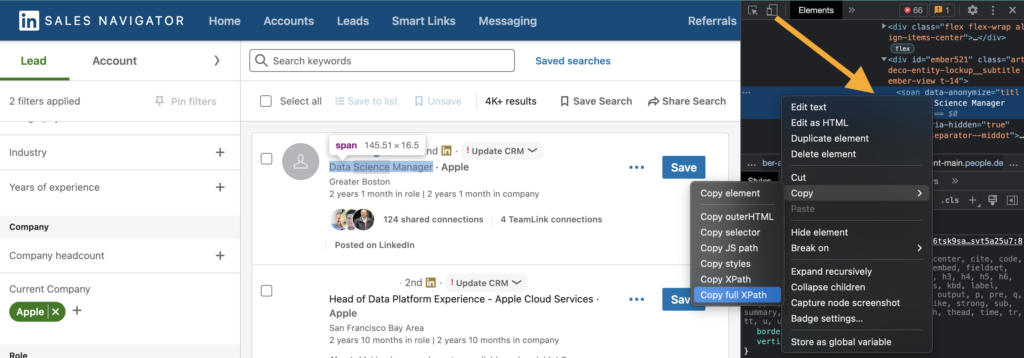
Scraping the data itself is relatively trivial once you understand the structure of the search results page. My strategy to find the path to the element I wanted was to right click and select “Inspect”. Then right-click on the highlighted HTML on the far-right (check out the orange arrow below) and go to Copy → Copy full XPath.
I stored the page’s search results in a pandas dataframe and concatenated the data from each new page onto the previous ones.
One last warning
Remember LI isn’t a big fan of scrapers. Your Chrome window will flash the dreaded 429 error if you hit their webpage too frequently. This error occurs when you exceed LI’s rate-limiting threshold. I am not sure what that threshold is or how exactly long you must wait before they reset your allowance.
I needed to scrape data from 300 companies whose returned search results ranged from 10 to 1000. My final dataset contained nearly 32,000 job titles. I only ran into the 429 error twice. Each time I simply paused my work for a couple hours before I restarting.