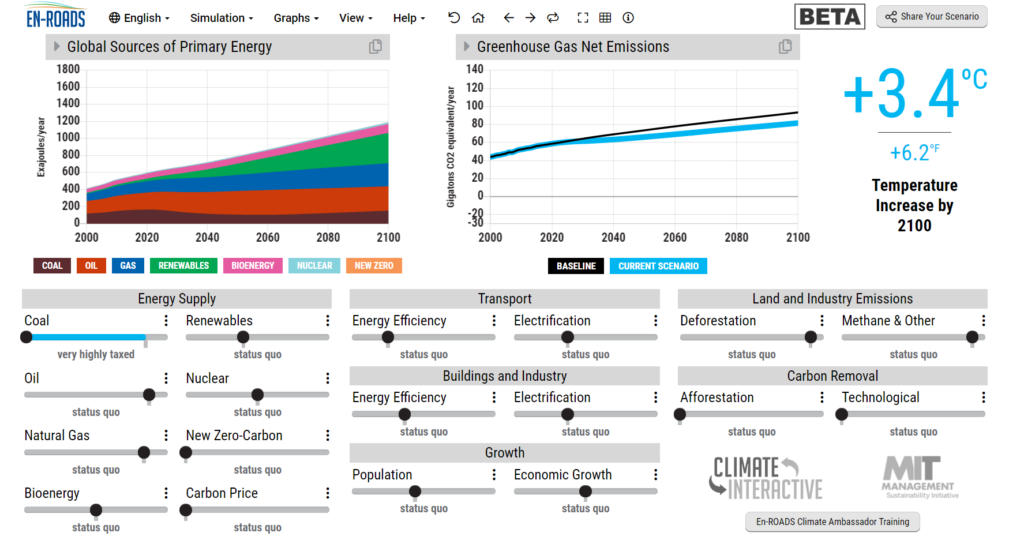
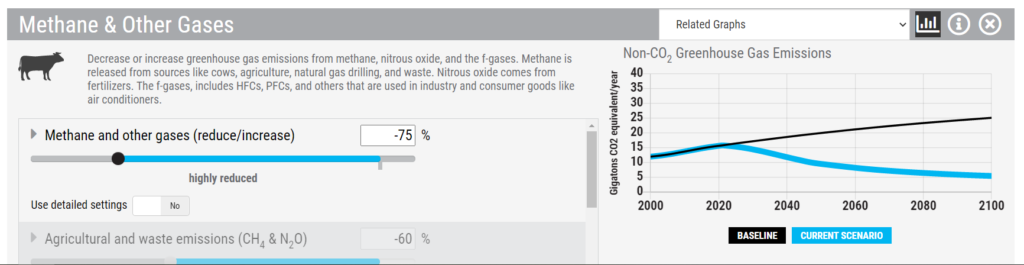
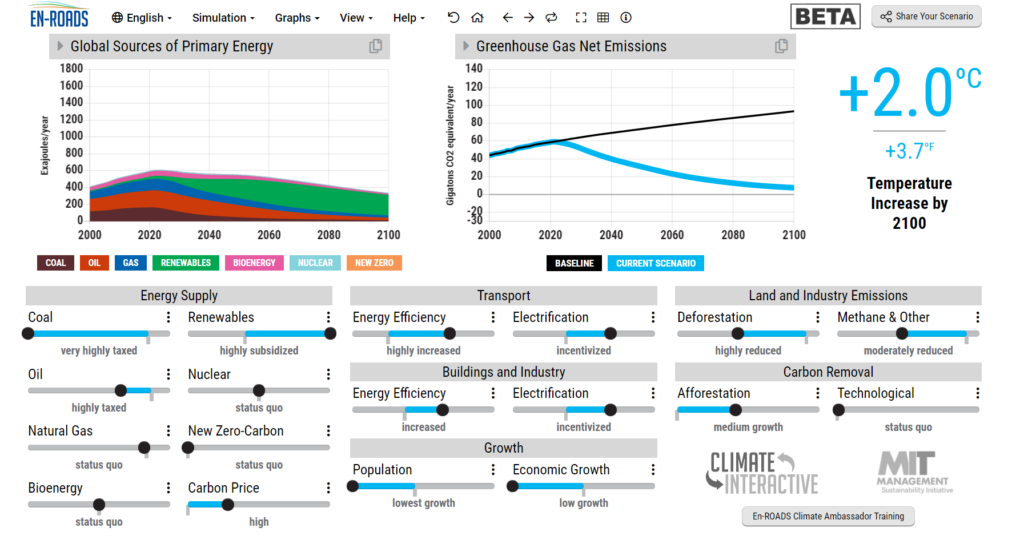
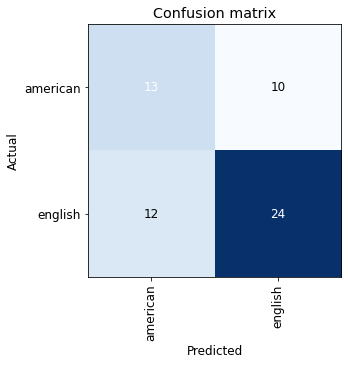
Data storytelling is arguably the most important skill an analyst or data scientist can possess. We can consider it the “last mile” of analytics—transforming a jumble of numbers and statistics into a memorable narrative.
This step is crucial because humans crave stories. We learn best from lessons packaged in narratives.
But forming our statistics into a compelling story requires making a series of choices that—in the wrong hands—can twist our results into a misleading conclusion.
To illustrate this potential danger, let me tell you a story.
The path not taken
Doug is a data analyst at Doober, a ride-sharing platform for dogs, and the bigwigs upstairs are noticing that more users than usual are defecting from the app after their first trip. Doug has been tasked with investigating why.
Doug digs into the data. This is his chance to shine in front of the execs! He analyzes anything he can think of that could be related to the root cause of these defections–user demographics, ride length, breed of the dog passengers.
Nothing seems to lead to any conclusions.
Finally, he checks driver tenure and discovers that nearly 90% of defections occur after a ride with a driver who had logged fewer than 5 trips.
“Aha!”, Doug thinks. “Perhaps inexperienced drivers don’t know how to handle these dogs just yet. We should pair new users with more experienced drivers to gain their trust in our platform.”
Satisfied with this insight and already imagining the praise he’ll receive from his manager, Doug starts to put together a presentation. But then, on a whim, he runs the numbers on driver experience across the entire population.
Doug finds that inexperienced drivers account for 85% of first-time trips for new users. This makes sense because Doober is a rather new platform, and most drivers haven’t had time to rack up many trips yet.
Is the difference in the fraction of trips logged by inexperienced drivers statistically significant between the defections and the wider population?
Doug could run a t-test against the trips that didn’t result in a defection to find out…or he could ignore this insight. After all, it doesn’t fit in his narrative, and Doug needs a narrative to present to the execs. Data storytelling is important, right?
Is Doug’s insight that most defections occur after a trip with an inexperienced driver wrong? No. But Doug has invited flawed conclusions in favor of telling a slick story.
Cherry-picking
The story of the Doug the analyst is an especially egregious example. Data contortions committed in the name of building a “narrative” are usually more subtle and unconsciously done.
An analyst may simply stop looking once they believe they’ve found an answer and have the data to back it up. After all, time is money.
Now I don’t mean to imply that all analysts are willfully distorting the statistics, like our friend at Doober. But with such a strong emphasis on data storytelling as a core component of the job, junior analysts may start to prioritize narrative over completeness.
Anyone who has read “How to Lie with Statistics” is familiar with the fact that a single dataset can produce diverging storylines, depending on how you slice and parse the data. Telling the story that best represents the data relies on an analyst’s professional integrity and judgment.
How to tell a data story with integrity
In an ideal world, analysts would complete their analysis in a vacuum of rationality before beginning to form a narrative. But that’s never how it really works.
Analysts must form narratives in their mind while analyzing data. Putting results in the context of a narrative allows them to ask the next logical question: if I’ve discovered x, what does that mean for y?
So how can we preserve our analytical integrity while exercising our story-telling creativity? The recommendations below are general best practices for any analysis but especially before committing yourself to a final data narrative.
- Ensure your data is sampled appropriately. Could your data collection method have been biased in any way? Do you have enough data points to draw a reasonably confident conclusion? Consider including confidence intervals on any supporting plots or in footnotes.
- Carefully consider your data’s distribution. Will your chosen statistical method best describe your data? For example, if you have a long-tailed population, it may be sensational to report a mean (“Average salary at our company is $500,000!”) when a median would better represent the answer to the question you are being asked (“A typical employee at our company makes $75,000 a year”).
- Be extremely explicit about correlation vs. causation. This was one of the major blunders Doug made. Just because defections appeared to be correlated with driver inexperience did not mean that driver inexperience caused user defections. Even if Doug presented his findings without any causal language, the execs would infer causation from the context in which he’s presenting.
Clearly differentiate between causation and correlation. Use bold font, stick it in a big yellow box on your slide, scream it from the rooftops.
- Use footnotes for any messy details. All stories require omission. Every author must constrain themselves to the most relevant details while continuing to engage their audience.
If you have additional facts and figures that support your story but don’t add to the overall narrative, include them as footnotes or within an addendum. Most execs just want the headline but you never know when you might be presenting to a particularly engaged manager who wants to dig into the details.
- Don’t be afraid to say “we don’t know”. The pressure to craft a data narrative can be strong, and confessing you don’t have a story seems tantamount to admitting failure.
But sometimes you just might not have the necessary data. The business might not have been tracking the right metric over time or the data could be so riddled with quality issues as to be unusable.
Learn from this experience, and implement a plan to start tracking new relevant metrics or fix the cause of the data quality issues. Look for other angles to attack the problem—perhaps by generating new data from a survey sent to defected users. It’s always better to admit uncertainty than to send the business on a wild goose chase.